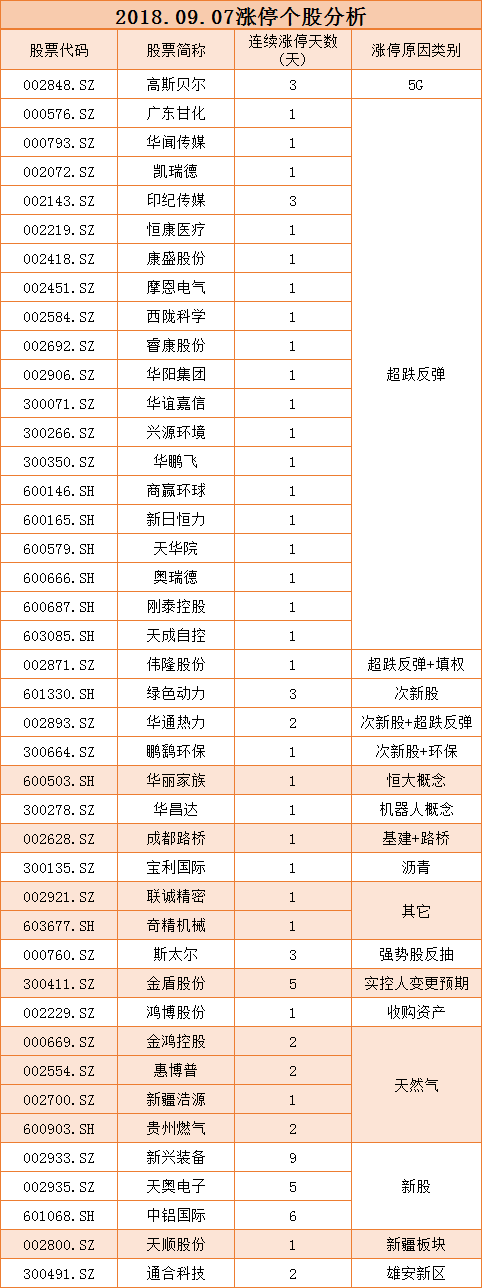
[600128股吧]数据挖掘过程中绝不能犯这11大错误
2024-01-31 15:16:12 来源:倾延资
数据剖析,数据发掘,模型,idmer
“走马消息,分享精选全球有价值的财经新闻”的新闻页面文章、图片、音频、视频等稿件均为自媒体人、第三方机构发布或转载。如稿件涉及版权等问题,请与
我们联系删除或处理,客服邮箱,稿件内容仅为传递更多信息之目的,不代表本网观点,亦不代表本网站赞同
其观点或证实其内容的真实性。
- 声音提醒
- 60秒后自动更新
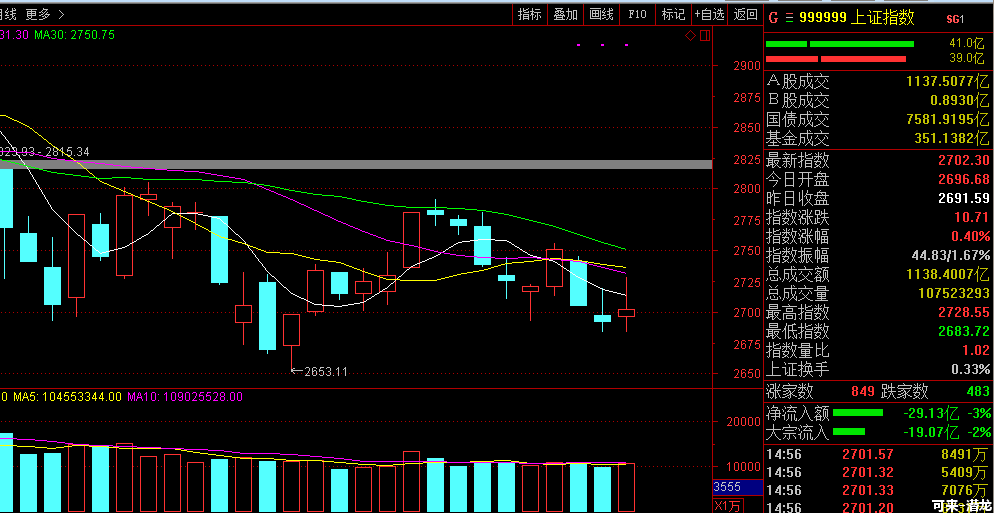
中国8月CPI年率2.3%,预期2.1%,前值2.1%。中国8月PPI年率4.1%,预期4.0%,前值4.6%。
08:00【统计局解读8月CPI:主要受食品价格上涨较多影响】从环比看,CPI上涨0.7%,涨幅比上月扩大0.4个百分点,主要受食品价格上涨较多影响。食品价格上涨2.4%,涨幅比上月扩大2.3个百分点,影响CPI上涨约0.46个百分点。从同比看,CPI上涨2.3%,涨幅比上月扩大0.2个百分点。1-8月平均,CPI上涨2.0%,与1-7月平均涨幅相同,表现出稳定态势。
08:00【 统计局:从调查的40个行业大类看,8月价格上涨的有30个 】统计局:从环比看,PPI上涨0.4%,涨幅比上月扩大0.3个百分点。生产资料价格上涨0.5%,涨幅比上月扩大0.4个百分点;生活资料价格上涨0.3%,扩大0.1个百分点。从调查的40个行业大类看,价格上涨的有30个,持平的有4个,下降的有6个。 在主要行业中,涨幅扩大的有黑色金属冶炼和压延加工业,上涨2.1%,比上月扩大1.6个百分点;石油、煤炭及其他燃料加工业,上涨1.7%,扩大0.8个百分点。化学原料和化学制品制造业价格由降转升,上涨0.6%。
08:00【日本经济已重回增长轨道】日本政府公布的数据显示,第二季度经济扩张速度明显快于最初估值,因企业在劳动力严重短缺的情况下支出超预期。第二季度日本经济折合成年率增长3.0%,高于1.9%的初步估计。经济数据证实,该全球第三大经济体已重回增长轨道。(华尔街日报)
08:00工信部:1-7月我国规模以上互联网和相关服务企业完成业务收入4965亿元,同比增长25.9%。
08:00【华泰宏观:通胀短期快速上行风险因素主要在猪价】华泰宏观李超团队点评8月通胀数据称,今年二、三季度全国部分地区的异常天气(霜冻、降雨等)因素触发了粮食、鲜菜和鲜果价格的波动预期,但这些因素对整体通胀影响有限,未来重点关注的通胀风险因素仍然是猪价和油价,短期尤其需要关注生猪疫情的传播情况。中性预测下半年通胀高点可能在+2.5%附近,年底前有望从高点小幅回落。
08:00【中国信通院:8月国内市场手机出货量同比环比均下降】中国信通院公布数据显示:2018年8月,国内手机市场出货量3259.5万部,同比下降20.9%,环比下降11.8%,其中智能手机出货量为3044.8万部,同比下降 17.4%; 2018年1-8月,国内手机市场出货量2.66亿部,同比下降17.7%。
08:00土耳其第二季度经济同比增长5.2%。
08:00乘联会:中国8月份广义乘用车零售销量176万辆,同比减少7.4%。
08:00央行连续第十四个交易日不开展逆回购操作,今日无逆回购到期。
08:00【黑田东彦:日本央行需要维持宽松政策一段时间】日本央行已经做出调整,以灵活地解决副作用和长期收益率的变化。央行在7月政策会议的决定中明确承诺将利率在更长时间内维持在低水平。(日本静冈新闻)
08:00澳洲联储助理主席Bullock:广泛的家庭财务压力并非迫在眉睫,只有少数借贷者发现难以偿还本金和利息贷款。大部分家庭能够偿还债务。
08:00【 美联储罗森格伦:9月很可能加息 】美联储罗森格伦:经济表现强劲,未来或需采取“温和紧缩”的政策。美联储若调高对中性利率的预估,从而调升对利率路径的预估,并不会感到意外。
08:00美联储罗森格伦:经济表现强劲,未来或需采取“温和紧缩”的政策。美联储若调高对中性利率的预估,从而调升对利率路径的预估,并不会感到意外。
08:00美联储罗森格伦:鉴于经济表现强劲,未来或需采取“温和紧缩的”政策。
08:00